
AI十級「找茬」選手,非這(zhè)個書生莫屬,節後(hòu)開(kāi)源!

新智元報道(dào)
編輯:好(hǎo)困桃子
爲了測試,研發(fā)團隊的大哥都(dōu)爬樹上了!什麼(me)模型竟然隻需 10% 的訓練數據,性能(néng)就(jiù)能(néng)超越同行,還(hái)會(huì)免費開(kāi)源?
考驗你眼力的時(shí)候到了!
隻看一眼,看出什麼(me)了嘛?
一塊木地闆?
隻答對(duì)了一半,其實圖中還(hái)有一隻喵。
下一個問題,這(zhè)是什麼(me)品種(zhǒng)的貓?啊...這(zhè)...

承認吧,你是辨别不出來的,但是這(zhè)個 AI「一眼」就(jiù)搞定了。
而這(zhè)麼(me)厲害的 AI 還(hái)有個詩意的名字,叫(jiào)「書生」。
更厲害的是,基于「書生」的通用視覺開(kāi)源平台 OpenGVLab 將(jiāng)會(huì)在春節後(hòu)全部公開(kāi)!
通用?視覺?
近幾年,語言模型的發(fā)展可謂是相當迅猛,百花齊放。
小到 3.54 億參數的 BERT,大到 5300 億參數的威震天-圖靈,以及 1.6 萬億參數的混合模型 Switch Transformer,順便還(hái)有首次常識問答超越人類的 KEAR。
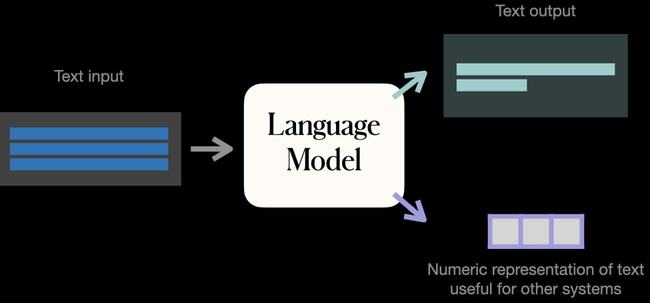
那麼(me),視覺模型這(zhè)邊又如何呢?
目前的 CV 領域主要是圖像匹配文本 CLIP 和文本生成(chéng)圖像 DALL·E這(zhè)種(zhǒng)單一模型。
但是 NLP 方向(xiàng)的各種(zhǒng)成(chéng)績都(dōu)表明,發(fā)展預訓練大模型不僅僅能(néng)夠處理多種(zhǒng)複雜任務、适用多種(zhǒng)場景和模态,而且能(néng)夠增加模型的複用率,減少了模型定制化開(kāi)發(fā)的開(kāi)銷進(jìn)而也降低了成(chéng)本。
而且,通用模型也是通往通用人工智能(néng)的必經(jīng)之路。
和通用語言模型類似,通用視覺模型的出發(fā)點和訓練思路也需要事(shì)先通過(guò)收集海量的無監督數據。然後(hòu)通過(guò)自監督等方式來訓練,得到通用的預訓練模型。最後(hòu)根據具體的下遊任務再將(jiāng)通用預訓練模型遷移到具體任務上去解決具體問題。
不過(guò),從任務角度看,通用視覺模型主要還(hái)是解決純視覺任務,也涉及一些視覺語言相關的多模态任務,而通用語言模型主要在解決語言相關的任務。而從模型訓練角度看,兩(liǎng)者的模型結構存在一些差異,具體訓練的監督形式也不一樣(yàng)。
但是想要實現模型的通用性,很難。
首當其沖的就(jiù)是,訓練數據不夠用。

訓練一個性能(néng)合格的深度學(xué)習模型,所需的數據采集量,少則十幾萬,多則千百萬張圖片,比如自動駕駛和人臉識别,對(duì)于數據的需求,達到十億級别,但性能(néng)仍未飽和。
在現實應用中,AI 需要大量業務數據和用戶互聯網行爲數據的融合,而企業可以應用的數據則非常有限。
數據都(dōu)采集不到,就(jiù)更不用提什麼(me)「高質量」了。
此外,模型對(duì)于數據的學(xué)習效率又低,無疑又是雪上加霜。
于是,N個任務就(jiù)需要開(kāi)發(fā)N個高度定制的模型同時(shí),每個模型在訓練的時(shí)候又需構建标注數據集進(jìn)行專項訓練,并持續進(jìn)行權重和參數優化。
時(shí)間、人力以及資源的成(chéng)本直接拉滿。
即便如此,依然有人想要挑戰一番。
2021 年 11 月,上海人工智能(néng)實驗室聯合商湯科技 SenseTime、香港中文大學(xué)、上海交通大學(xué)共同發(fā)布了新一代通用視覺技術體系——「書生」(INTERN)。

論文地址:https://arxiv.org/abs/2111.08687
通才是如何練成(chéng)?
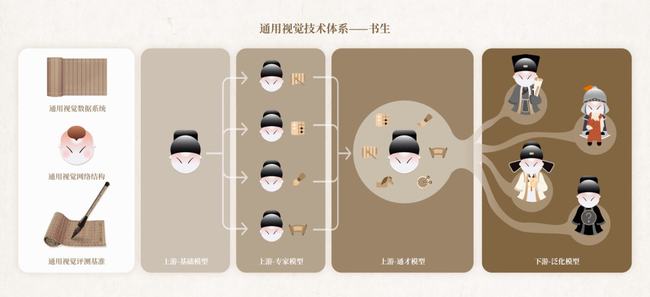
作爲通用視覺技術體系的「書生」有三個基礎設施模塊,分别爲:
通用視覺數據系統(GV-Dataset)
通用視覺網絡結構(GV-Architecture)
通用視覺評測基準(GV-Benchmark)

這(zhè)三個基礎模塊有什麼(me)作用?
它們就(jiù)像「百科全書」、「高樓基底」一樣(yàng)。「書生」通才的道(dào)路上學(xué)到的海量知識和建模、評測等基礎能(néng)力就(jiù)靠這(zhè)三個基礎模塊了。

具體點講,其中,在通用視覺數據系統中包含了大量的高質量數據集:
1. 超大量級精标注數據:除了整合現有開(kāi)源數據集,還(hái)進(jìn)行了大規模數據圖像标注任務,涵蓋了圖像分類,目标檢測以及圖像分割等任務,數據總量級達到 40M。
分類任務數據量級爲 71M,其中包含 9 個公開(kāi)數據集 28M,以及自标注數據 43M。目标檢測任務數據量級爲 4M,其中包含 3 個公開(kāi)數據集 3M,以及自标注數據 1M。
2. 超大标簽體系:總标簽量級達到 119K,幾乎覆蓋了所有現有開(kāi)源數據集,在此基礎上擴充了大量細粒度标簽。
極大地豐富了圖像任務的标簽,提供了更爲合理的組織方式,以及可擴展的标簽延伸策略。
3. 首次提出視界(realm)概念:結合「書生」标簽體系,可以極大提升預訓練模型的性能(néng)。

在通用視覺網絡結構中,MetaNet 是一種(zhǒng)自研的模型搜索網絡,它最大的變種(zhǒng)包含百億的參數量,是當今最大的視覺網絡之一。
這(zhè)個網絡結構結合了視覺卷積和前沿的視覺自關注機制,通過(guò)大規模強化學(xué)習網絡結構搜索算法,取得最佳算子組合,達到模型效率和效用的最大化。
在相同的資源限制的情況下,「書生」的視覺網絡獲得在不同視覺任務下更優異的精度。
在獲得超大規模的視覺神經(jīng)網絡以賦能(néng)計算機視覺社區的研究的同時(shí),「書生」的網絡支持靈活地進(jìn)行不同規模的調整,以适應不同程度的工業化落地時(shí)的運算能(néng)力需求,賦能(néng)視覺算法的工業落地。
有了這(zhè)樣(yàng)的網絡結構之後(hòu),就(jiù)可以對(duì)其進(jìn)行了從「基礎模型-專家-通才」模型的訓練策略,極大地增強這(zhè)種(zhǒng)網絡結構的泛化能(néng)力。

第三個便是視覺評測基準,它就(jiù)像是一個「擂台」,收集了 4 種(zhǒng)類型共 26 個下遊任務。
不僅包括常規分類任務還(hái)包括細粒度分類任務,還(hái)包括醫療圖像等特殊領域的分類任務、行人檢測等熱門檢測任務,擴展到分割與深度任務,可以很好(hǎo)地衡量模型的泛化能(néng)力。
這(zhè)一視覺評測基準還(hái)引入了百分比樣(yàng)本(percentage-shot)的設置。
亮點在于,下遊任務訓練數據被(bèi)壓縮的同時(shí),還(hái)可以很好(hǎo)地保留原始數據集的長(cháng)尾分布等屬性。

「書生」除了這(zhè)三個基礎設施模塊之外,還(hái)有四個訓練階段模塊。
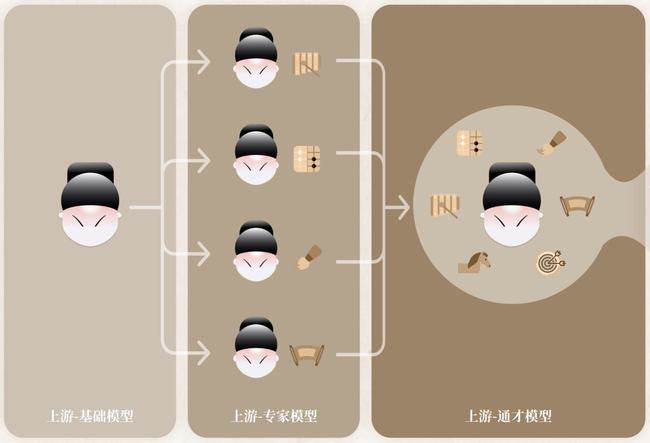
在「書生」(INTERN)的四個訓練階段中,前三個階段位于該技術鏈條的上遊,在模型的表征通用性上發(fā)力。
第一階段,「基礎能(néng)力」的培養需要經(jīng)過(guò)一個跨模态的預訓練過(guò)程,通過(guò)大量的圖像-文本對(duì)進(jìn)行通用模型的預訓練,讓其學(xué)到廣泛的基礎常識,爲後(hòu)續學(xué)習階段打好(hǎo)基礎;
第二階段,培養「專家能(néng)力」,即多個專家模型各自學(xué)習某一領域的專業知識,讓每一個專家模型高度掌握該領域技能(néng),成(chéng)爲專家;
第三階段,培養「通用能(néng)力」,此時(shí)的通才模型繼承了大規模多模态的預訓練信息,也融合了多樣(yàng)的感知任務的信息,「書生」在各個技能(néng)領域都(dōu)展現優異水平,并具備快速學(xué)會(huì)新技能(néng)的能(néng)力。
通過(guò)前三個模塊階梯式的學(xué)習,「書生」具備了高度的通用性和良好(hǎo)的泛化能(néng)力。
當進(jìn)化到位于下遊的第四階段時(shí),系統將(jiāng)具備「遷移能(néng)力」,此時(shí)「書生」學(xué)到的通用知識可以應用在某一個特定領域的不同任務中。
從實驗結果來看,相較于當前最強 CV 模型 CLIP,「書生」在準确率和數據使用效率上均取得了大幅提升。
具體來講,在分類識别、目标檢測、語義分割及深度估計四大任務 26 個數據集上,「書生」的平均錯誤率分别降低了 40.2%、47.3%、34.8% 和 9.4%。

同時(shí),「書生」隻需要1/10 的下遊數據,就(jiù)幹翻了 CLIP 基于完整下遊數據的準确度。

書生不是「書呆子」
光學(xué)不去練,不會(huì)用,還(hái)是沒(méi)啥本事(shì)。
要明确的是,商湯的「書生」可不是一個書呆子。
怎麼(me)講?
首先,它能(néng)夠舉一反三。
舉個形象點的栗子,比如讓「書生」識别花的種(zhǒng)類,每一類隻需要提供 2 個訓練樣(yàng)本,識别準确率高達 99.7%。

這(zhè)個花卉數據集由 102 種(zhǒng)英國(guó)常見的花組成(chéng),每個類别有 40 至 258 張圖片。其中包含有很大的比例、姿勢和光線變化。

它不僅有觸類旁通的能(néng)力,而且在自動駕駛、智慧城市、智慧醫療等場景均已經(jīng)實現了落地應用。
就(jiù)拿自動駕駛來說(shuō)吧,要想不成(chéng)爲馬路殺手,一套 CV 模型需要能(néng)夠識别各種(zhǒng)物體,包括交通标志,車道(dào)線識别等,還(hái)得預測出與障礙物的距離,行人檢測等等。

對(duì)于這(zhè)些任務,單一視覺模型是無法勝任的。
而「書生」技術體系從數據、模型等各個方面(miàn)出發(fā),對(duì)自動駕駛感知模型,尤其是長(cháng)尾類别和場景非常友好(hǎo),在小樣(yàng)本甚至是零樣(yàng)本的應用場景下表現明顯優于既往模型。
其實,在實際場景應用中,數據都(dōu)存在長(cháng)尾分布的現象,少量類别占據大多數樣(yàng)本,而大量類别僅有少量樣(yàng)本。
在智慧城市中也是同樣(yàng)的道(dào)理,面(miàn)對(duì)很多長(cháng)尾、碎片化場景就(jiù)不得不祭出通才「書生」了。
生活中,我們經(jīng)常會(huì)見到城市街道(dào)上的井蓋頻頻丢失的問題。

如果 CV 模型沒(méi)有關注城市治理的長(cháng)尾問題,偷井蓋問題很難得到解決。況且,井蓋也有很多種(zhǒng)樣(yàng)子。
但是,這(zhè)對(duì)于通才「書生」來講都(dōu)是小 case。隻要每一類提供 2 個訓練樣(yàng)本,問題不就(jiù)搞定了嗎。

因爲它已經(jīng)在訓練階段被(bèi)「喂下」大量數據成(chéng)爲通才,隻需要看到少量樣(yàng)本,就(jiù)具備了舉一反三的能(néng)力。
有了「書生」的加持,不僅可以預防井蓋丢失,還(hái)能(néng)實現事(shì)後(hòu)追責的精細化管理。

此外,智慧制造、智慧醫療等應用中還(hái)會(huì)存在很多類似的長(cháng)尾場景,而通用視覺「書生」的推出能(néng)夠讓業界以更低的成(chéng)本獲得擁有處理多種(zhǒng)下遊任務能(néng)力的 AI 模型。
并以其強大的泛化能(néng)力支撐實際場景中大量小數據、零數據等樣(yàng)本缺失的細分和長(cháng)尾場景需求。

書生(INTERN)技術體系可以讓 AI 模型處理多樣(yàng)化的視覺任務
這(zhè)些暴力計算下的 AI 場景需要強大的算力作爲支撐,這(zhè)時(shí)候 SenseCore 商湯 AI 大裝置正好(hǎo)就(jiù)派上用場了。
AI 大裝置正是通過(guò)超強的算力基礎,爲人工智能(néng)的研發(fā)、創新和應用提供源動力。

正如商湯科技研究院院長(cháng)王曉剛所提到的那樣(yàng):
「書生」通用視覺技術體系是商湯在通用智能(néng)技術發(fā)展趨勢下前瞻性布局的一次嘗試,也是 SenseCore 商湯 AI 大裝置背景下的一次新技術路徑探索。 「書生」承載了讓人工智能(néng)參與處理多種(zhǒng)複雜任務、适用多種(zhǒng)場景和模态、有效進(jìn)行小數據和非監督學(xué)習并最終具備接近人的通用視覺智能(néng)的期盼。 希望這(zhè)套技術體系能(néng)夠幫助業界更好(hǎo)地探索和應用通用視覺 AI 技術,促進(jìn) AI 規模化落地。
不過(guò),想要成(chéng)爲一個優秀的通用視覺模型,「書生」還(hái)有三個挑戰需要解決:
1. 模型優化速度的提升
對(duì)于一個好(hǎo)的預訓練模型,往往需要更大更好(hǎo)的網絡結構,以及大規模的數據,這(zhè)就(jiù)會(huì)導緻幾天甚至幾周的模型訓練時(shí)間,如何在保持表征能(néng)力的同時(shí),大幅度加速模型的訓練過(guò)程,具有非常重大的現實意義。
2. 更大範圍内的通用能(néng)力仍待探索
書生模型,可以很好(hǎo)地在常見的視覺任務裡(lǐ)達到通用的效果。在跨度較大的領域,比如超分等底層視覺任務,書生模型還(hái)有很大的進(jìn)步空間。
3. 大模型到小模型的轉變
將(jiāng)大模型的表征能(néng)力無損失的遷移到可部署到終端設備上的小模型,對(duì)于預訓練模型的推廣有非常大的價值。
One More Thing
要問這(zhè)個模型好(hǎo)不好(hǎo)做?
研發(fā)急得都(dōu)直「爬樹」!

爲了測試模型在 zero-shot 下的精度如何,書生研發(fā)團隊的模型科學(xué)家都(dōu)親自上演了「爬樹」特别節目。通過(guò)創造特殊場景,以随機生成(chéng)圖片,去考驗模型能(néng)力。
(研究需要,大家請勿模仿^_^)
「書生」看到後(hòu),歪嘴一笑。
這(zhè)不就(jiù)是「爬樹」嘛,置信度 0.96 給你。

而且有趣的是,「書生」模型還(hái)注意到了樹上人眼都(dōu)很容易忽略的繩子。
可能(néng),這(zhè)就(jiù)是「明察秋毫」吧!

未來,「書生」要做的一件事(shì)情:
基于「書生」的通用視覺開(kāi)源平台 OpenGVLab 也將(jiāng)在今年年初正式開(kāi)源,産學(xué)研一道(dào)共創通用 AI 生态!

而即將(jiāng)開(kāi)源的 OpenGVLab,正是基于「書生」的通用視覺開(kāi)源平台。
其中的網絡結構除了商湯自研的 MetaNet,還(hái)包含大家普遍使用的 ResNet, MobileNet, ViT, EfficientNet 等,以滿足不同場景的應用,賦能(néng)計算機視覺。
然而,「書生」的布局不止于此。
OpenGVLab 將(jiāng)與上海人工智能(néng)實驗室此前發(fā)布的 OpenMMLab、OpenDILab 一道(dào),共同構築開(kāi)源體系 OpenXLab,持續推進(jìn)通用人工智能(néng)的技術突破和生态構建。
「書生」研發(fā)團隊的一位成(chéng)員調侃道(dào),「随著(zhe)書生模型精度越來越高,我們的辦公樓層越來越高。」

開(kāi)源的「書生」,前景廣闊。